
pwn学习心得
c语言
c标准库
c标准库包含了一组头文件,这些头文件提供了许多函数和宏,用于处理输入输出、字符串操作、数学计算、内存管理等常见编程任务。
若要使用C标准语言库中的函数,首先需要包含相应的头文件。例如,如果要调用printf函数,程序中需包含<stdio.h>头文件。
#include <stdio.h> |
c标准库大致分为如下几类
输入输出操作 如<stdio.h>
字符串处理 如<string.h>
数学计算 如<math.h>
内存管理 如<stdlib.h>
时间处理 如<time.h>
所以头文件的功能如下图所示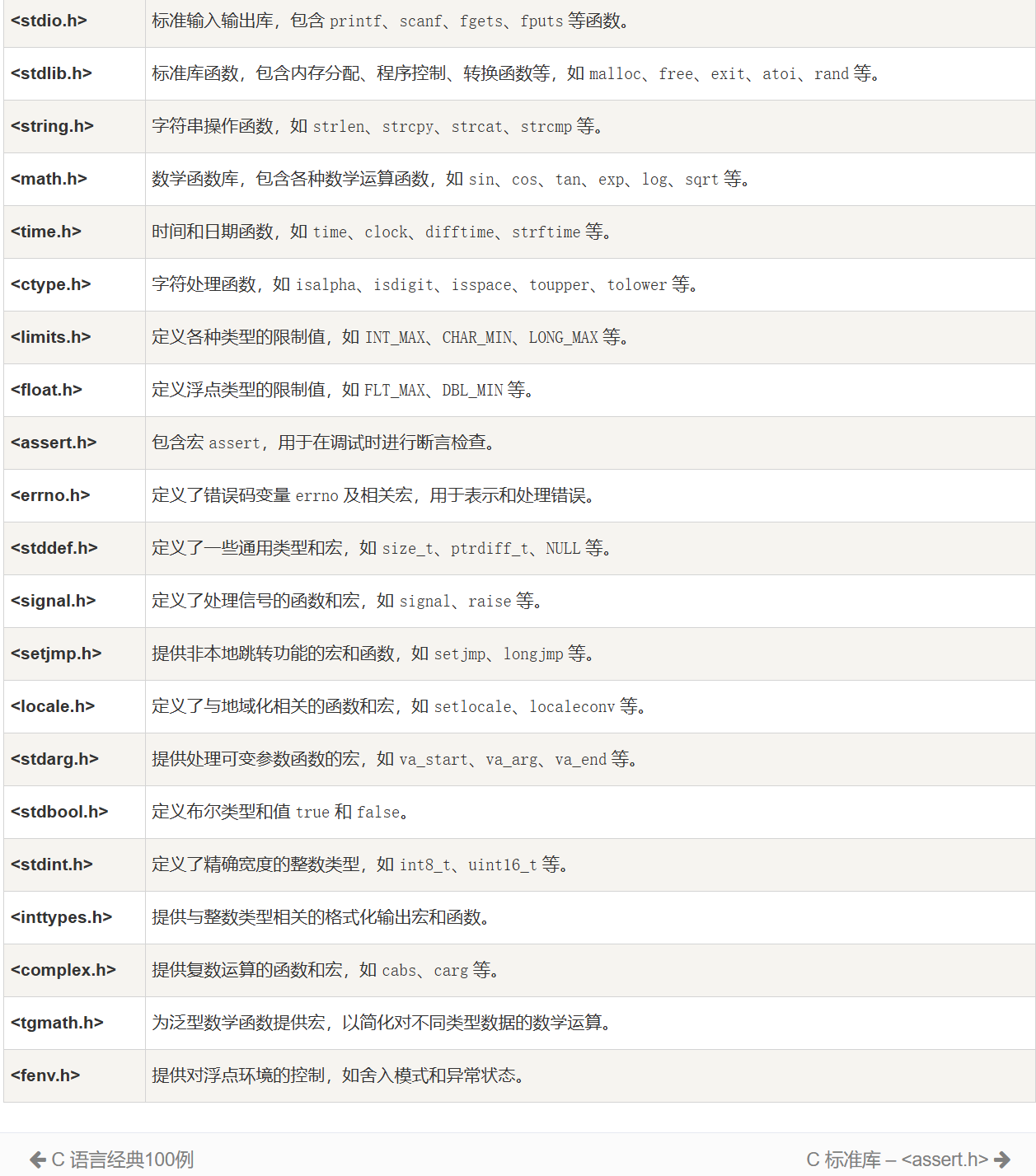
如需更详细了解可去https://www.runoob.com/cprogramming/c-standard-library.html
c语言不安全函数
gets
gets读取用户输入文本,但gets不会检查缓冲区大小,这很有可能导致栈溢出。- 解决方法:
使用fgets函数代替gets函数,限制读取输入文本的大小
strcat
连接两个字符数组中的字符串,把字符串2接到字符串1的后面,结果放在字符串1中,函数调用后得到的值就是是字符串1的地址
解决办法:
使用
strncat来代替strcat,strncat允许指定复制的最大字符数.
strcmp
比较两个字符串的内容。但它不处理
NULL指针或空字符串。如果输入的字符串是NULL,则会导致程序崩溃。解决办法:
在使用
strcmp之前,确保传入的字符串指针已初始化,并且不是空指针。否则,传递空指针可能导致程序崩溃。
scanf
scanf()在处理输入时没有明确限制输入的长度,比如使用%s时,没有限定输入长度,可能导致缓冲区溢出。解决办法:
使用
%Ns来限制输入的最大长度,或使用fgets()结合sscanf()来更好地控制输入
strcpy
将将源字符串复制到目标缓冲区,它也不会检查目标缓冲区的大小,从而导致栈溢出。
解决方法:
可以使用strncpy(),它允许指定复制的最大字符数,但要保留一位长度用来储存\0(size-1).
由我个人浅薄的认知而言,大部分c语言危险函数都是不检查缓存区导致的,所导致的问题基本上也是栈溢出这类,解决办法往往也是限制读取字符的大小,防止其超过缓冲区的大小。
c语言常见漏洞
在了解漏洞之前,我们需要简单了解一下什么是**栈和堆**。
栈(Stack)
1. 内存分配方式
- 栈是一种后进先出(LIFO,Last In First Out)的数据结构,就是说压栈的时候后面的数据先压到栈内,弹栈的时候前面的数据会弹出。每次函数调用时,局部变量、函数参数和返回地址等信息会被压入栈中。
- 栈的分配是自动的,当函数调用时,系统会自动为其分配内存;当函数返回时,这些内存会被自动释放。
2. 存储内容
- 栈主要存储局部变量、函数参数、返回地址以及栈帧相关的元数据。
- 每个线程都有一个独立的栈,栈空间较小(通常在几MB的范围内),它的大小在程序开始时就确定了。
3. 内存分配速度
- 栈上的内存分配和释放速度非常快,因为栈是连续的内存区域,分配和释放只是调整栈指针(
ESP或RSP)的位置。由于栈的结构简单,系统只需要移动栈指针,无需进行复杂的管理。
4. 生命周期
- 栈上的数据是临时的,局部变量在函数调用期间有效,当函数返回时,栈上的内存自动释放,局部变量不再有效。这意味着栈上的数据只能在有限的时间内存在,函数结束后,栈上的数据就不再可用。
5. 内存限制
- 栈的大小是有限的,通常系统为每个线程分配一定大小的栈(例如4MB或8MB)。如果递归太深或者分配了太多的局部变量,可能会导致栈溢出(Stack Overflow)。
堆(Heap)
1. 内存分配方式
- 堆是一块动态分配的内存区域,用于存储在程序运行期间动态申请的内存(通过
malloc、calloc、new等函数或操作符)。 - 堆内存的分配和释放是手动的,程序员负责申请内存并在不需要时释放内存。如果忘记释放,就会导致内存泄漏。
2. 存储内容
- 堆主要用于存储动态分配的数据,例如大型数据结构(如数组、链表、树等)和需要跨函数生命周期的数据。
- 堆中的内存区域较大,通常比栈的内存空间大得多,大小可以根据需要动态增长(取决于系统的可用内存)。
3. 内存分配速度
- 相比栈,堆上的内存分配和释放要慢得多,因为堆的内存是由操作系统管理的,需要查找空闲块、更新内存管理结构等操作,这些都增加了时间开销。
4. 生命周期
- 堆上的数据具有更长的生命周期,内存可以一直存在,直到程序手动释放(调用
free)。这使得堆内存非常适合存储需要跨多个函数或线程使用的数据。 - 如果程序不及时释放堆内存,会导致内存泄漏,长时间运行的程序可能会因为内存泄漏导致内存耗尽。
5. 内存限制
堆的大小没有栈那么严格的限制,它可以动态增长,理论上可以使用系统可用内存的绝大部分。然而,堆内存的使用如果管理不当,可能会导致内存碎片化,降低分配效率。
| 栈(stack) | 堆(head) | |
|---|---|---|
| 内存分配方式 | 由编译器自动分配和释放 | 由程序员手动分配和释放 |
| 分配速度 | 非常快,直接在栈顶分配或释放 | 较慢,内存分配需要进行复杂的管理操作 |
| 存储内容 | 局部变量、函数参数、返回地址 | 动态分配的内存块,适合存储大对象或动态数据 |
| 内存大小 | 栈空间通常较小(系统设置有限),如几MB | 堆空间通常较大,受限于系统可用内存量 |
| 访问方式 | 通过栈帧直接访问(LIFO),效率高 | 通过指针访问,效率较低 |
| 生命周期 | 随函数调用开始,随函数返回结束收 | 程序员控制,生命周期较长 |
| 安全性 | 相对安全,有栈溢出保护(如栈金丝雀、ASLR) | 内存泄漏、双重释放、UAF等问题 |
| 用途 | 用于局部变量、函数参数、临时数据等 | 用于动态数据结构(如链表、树、图等)或大型对象 |
| 增长方向 | 从高地址向低地址增长 | 从低地址向高地址增长 |
漏洞
1. 缓冲区溢出(Buffer Overflow)
缓冲区溢出是:指程序试图将数据写入超出预定缓冲区大小的内存地址。这种情况通常发生在数组、字符串等固定大小的内存区域上。
缓冲区溢出并不局限于栈或堆,它可以发生在任意的内存区域。
2. 栈溢出(Stack Overflow)
栈溢出是:程序试图在栈上分配超出栈空间限制的数据量时,导致栈内存超出预分配的区域。
其成因大致分为两种:
- 一是存储的数据超过预分配的栈空间;
- 二是递归函数没有设置正确的结束条件,一直进行下去,直到占满栈的空间。
3. 堆溢出(Heap Overflow)
堆溢出是:程序在使用动态内存分配时写入的数据超过了分配的空间大小堆内存,可能会导致覆盖其他堆中的数据或破坏堆管理器的元数据,进而导致程序崩溃或安全漏洞。
成因:
分配内存时没有正确计算所需的内存大小。
缓冲区在输入数据时没有进行边界检查。
动态内存分配之后没有适当检查返回值。
4. 内存泄漏(Memory Leak)
内存泄漏是:程序动态分配了堆内存后未能正确释放,导致占据的内存块无法访问,没办法被释放,随着程序占用的内存不断增加,系统可用内存逐渐减少,最终导致程序崩溃。
成因大致如下:
- 忘记释放内存,没有使用
free()来释放内存 - 程序在动态分配内存后,如果不小心覆盖了指向这块内存的指针
5. 使用后释放漏洞(Use-After-Free, UAF)
UAF漏洞是:程序在释放了堆内存后,继续访问或修改已释放的内存,由于该内存块已经被标记为可供再分配或是已被其他数据占用,继续使用可能导致程序崩溃或攻击者利用该漏洞执行恶意代码。
成因:
程序过早的释放了某个指针指向的内存,而这个指针仍然被其他代码使用
程序有可能多次释放同一块内存,可能导致指针变成悬空指针
复杂的指针引用关系
**6.格式化字符串漏洞(Format String Vulnerability) **
格式化字符串漏洞是:程序在处理用户输入的格式化字符时没有进行适当的验证,导致攻击者可以通过恶意构造的输入来控制程序。
成因:程序在调用格式化输出函数时,错误地将用户输入的内容作为格式化字符串参数,例如(%d,%x)使用,而没有进行适当的过滤和验证
7. 双重释放(Double Freee)
双重释放是:程序中尝试释放已经被释放过的内存。双重释放漏洞会导致程序的不稳定性
成因:
- 程序多次调用
free() - 指针被多次引用,错误地释放了同一块内存
- 程序的控制流错误地执行了内存释放操作,导致相同的指针多次被释放。
8. 越界一位漏洞(Off-by-One Error)
越界—位漏洞是:程序试图访问数组,缓冲区或者其他线性数据结构中的边界元素时,由于计算或是逻辑错误,访问到多出来的一位。
成因:
- 数组的访问超出了数组的合法引索范围
- 处理字符串的时候多访问或是少访问一位字符
- 循环条件中边界设置错误,导致超出范围
越界一位漏洞虽然类似于缓冲区溢出,但是它的范围比较小,一般仅仅超出一位,而不像缓冲区一处那样大范围超出。
分析及其危害
code 1
#include <stdio.h> //引入标准输入输出库 |
使用了gets()函数,若读取的文本超出缓存区大小,就有可能造成漏洞
code2
#include <stdio.h>//引入标准输入输出库 |
使用了危险函数strcmp,若输入的密码为空,即NULL就有可能导致程序崩溃.
code 3、
#include <stdio.h> //引入标准输入输出库 |
使用了read(0, buf, 0x200); 企图读取512字节到256字节大小的 buf ,这将导致缓冲区溢出。
code 4、
#include <stdio.h>//引入标准输入输出库 |
add函数那一块,使用了scanf函数,尽管检查了size的大小,但是没有考虑size的值是否为负数,有可能导致整数溢出。
在edit函数那一块,使用了read将用于输入的content读取给notes[idx].size,若content的大小超出notes[idx].size,就有可能导致UAF漏洞。
汇编语言
汇编语言
我们平日里学习的编程语言,属于高级语言,但计算机无法直接理解,需要通过编译器(例如gcc)将高级语言转换成二进制代码(操作码),这样计算机才能理解。计算机真正能够理解的是低级语言,它专门用来控制硬件。而汇编语言就是低级语言,用于直接操作计算机硬件,例如寄存器、内存等等。
对于人来说,二进制程序是不可读的,难以看不出来机器究竟干了什么。为了解决这个问题,于是就有了汇编语言。汇编语言是机械指令的文本形式,与指令是一一对应。比如,加法指令00000011写成汇编语言就是 ADD。只要还原成二进制,汇编语言就可以被 CPU 直接执行。
这里又有了个新的概念,什么是指令。指令通常由操作码,操作数和寻访地址组成
机械指令:CPU可直接识别和执行的二进制编码
汇编指令:机器指令的助记符(缩写居多),同机器指令一一对应。
- 汇编指令
- 伪指令:没有对应的机器码,由编译器执行,计算机并不执行。
- 其他符号:如+、-、*、/等。
寄存器(Registers)
寄存器(Registers)是计算机数据储存方式之一,它位于CPU内部,是CPU内部元件之一,用于暂存CPU执行指令和数据。在储存器中,寄存器的处理速度是最快的(1 ns),同时也是造价最昂贵。
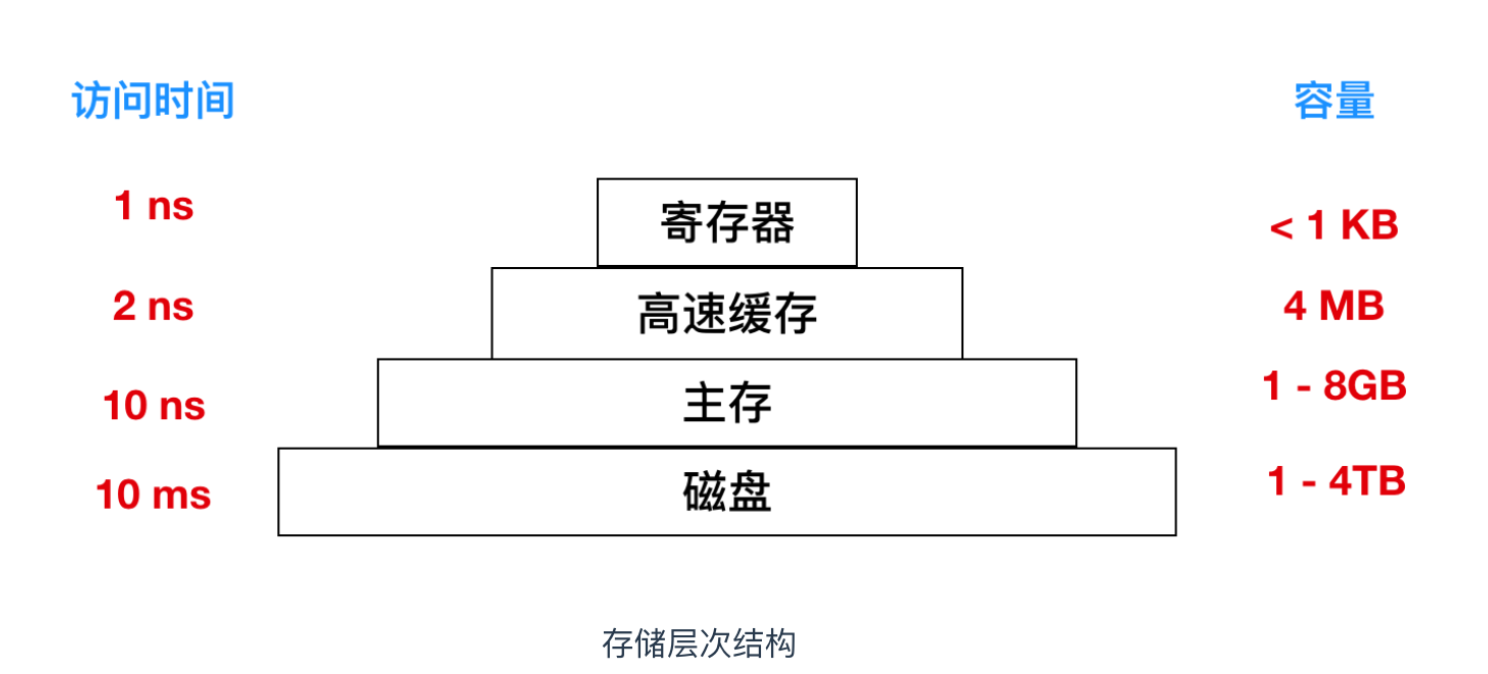
在更具体的了解寄存器之前,我们要简单了解**CPU**内部的架构
CPU架构
CPU
CPU :中央处理器,是计算机硬件的核心部件,大致由运算器,控制器,寄存器和总线组成。前三个部分由总线连接起来。
其中,运算器大致分为:
累加器ACC
寄存器
算术逻辑单位ALU等等
控制器则分为:
控制单元CU
指令寄存器IR
程序计数器PC等等
粗浅了解一下CPU的核心组件,大致如下:
控制单元(Control Unit, CU)
- 功能:取指令,解释这些指令,并发送到CPU的各个部分来执行指令。
- 工作原理:通过协调其他单元(如ALU、寄存器)的工作,控制单元确保每个指令按照设定的顺序执行。
算术逻辑单元(Arithmetic Logic Unit, ALU)
- 功能:ALU是CPU中执行算术运算(加减乘除)和逻辑运算(与或非等)的部分。
- 工作原理:ALU从寄存器获取操作数,执行操作并将结果存储到寄存器中。
寄存器(Registers)
- 功能:寄存器是CPU中的小型存储单元,用于暂时保存数据和指令。
- 重要性:寄存器能够极大提高CPU处理数据的效率,它们与CPU直接连接,访问速度极快(1ns)。*
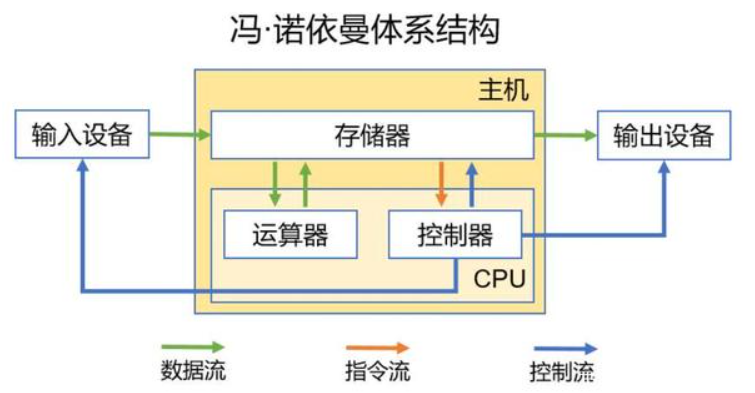
冯诺依曼体系
1945年提出的冯诺依曼体系结构是现代计算机的基础。这套理论的基本思想即为:指令和数据存储在同一内存中,由此程序指令和数据的宽度相同。此外,他还提出了计算机的三个原则,即为计算机由五个部分组成(运算器,控制器,储存器,输出设备,输入设备)、程序存储执行和二进制逻辑。
根据冯诺依曼体系,CPU的工作分为以下 5 个阶段:取指令阶段、指令译码阶段、执行指令阶段、访存取数和结果写回。
取指令:CPU从内存中获取指令。程序计数器(PC)指向下一条指令的地址,CPU将该地址中的指令加载到IR中。
指令编译:CPU解码指令,识别操作码(opcode)和操作数。
执行指令:CPU执行译码后的指令,使用算术逻辑单元(ALU)进行计算。
访存取数:若指令需要访问内存,CPU会在此阶段进行内存访问。对于加载指令,从内存中读取数据;对于存储指令,将数据写入内存。
结果回读:将执行结果写回寄存器或内存。
寄存器类型:
通用寄存器(General Purpose Registers)
通用寄存器用于存储数据和地址。每个寄存器可以作为32位(在x86-32位架构中)或64位(在x86-64位架构中)来操作。在32位模式下,寄存器前缀为E,在64位模式下,前缀为R。这些寄存器可用于存储整数、地址、结果等数据。
累加寄存器AX(Accumulator)
·用于算术运算,很多指令默认使用它进行结果存储。
- EAX(32位)
- AX(16位)
- RAX(64位)
基址寄存器BX(Base Register)
·通常用于存储基址(Base Address),例如内存中的数据地址。
- EBX(32位)
- BX(16位)
- RBX(64位)
计数寄存器CX(Count Register)
·用于循环计数操作和字符串操作。
ECX(32位)
CX(16位)
RCX(64位)
数据寄存器DX(Date Register)
·在乘除和I/O,通常用于存储被除数或商和余数。
- EDX(32位)
- DX(16位)
- RDX(64位)
其中,AX、BX、CX、DX 都可以独立当作两个8位寄存器来使用。
- AX 分为 AH 和 AL
- BX 分为 BH 和 BL
- CX 分为 CL 和 CL
- DX 分为 DH 和 DL
- 其他
- 源索引寄存器 SI(Source Index): 通常用于字符串操作中,作为源数据的指针。
- 目标索引寄存器 DI(Destination Index): 通常用于字符串操作中,作为目标数据的指针。
- 基址指针寄存器 BP(Base Pointer): 通常用于存储栈帧基地址,帮助访问函数参数和局部变量。
- 栈指针寄存器 SP (Stack Pointer Register): 指向当前栈顶,用于管理函数调用和局部变量。
- 64位架构新增的寄存器 R8-R15: 在x86-64架构中,为增强性能,额外增加了8个通用寄存器(R8到R15)。这些寄存器没有直接的 32 位版本,但可以通过细分为 32 位、16 位和8位子寄存器进行操作。

段寄存器(Segment Registers)
段寄存器用于分段内存寻址,早期x86架构通过分段机制来管理内存。虽然现代处理器很少直接使用段寄存器,但在保护模式下它们仍然有一定作用。
- 代码段寄存器 CS(Code Segment) :保存当前代码段的基址,决定当前执行的代码所在的段。
- 数据段寄存器 DS(Data Segment):保存数据段的基址,决定数据存储位置。
- 栈段寄存器 SS(STack Segement):保存栈段的基址,指向当前栈所在的内存段。
- ES、FS、GS:用于额外的段存取,特别是在特定的系统调用或结构访问中有特殊用途。
指令指针寄存器(Instruction Pointer)
- EIP:指向下一条将要执行的指令的内存地址,通常随着指令的执行自动增加。
- RIP:存储当前执行的指令地址。
状态寄存器(Flags Register)
状态寄存器FLAGS存储处理器当前的状态信息,特别是在条件判断、跳转等操作中起作用。
内存栈(Memory stack)
内存栈(stack)是存储函数调用的信息、局部变量、返回地址等的重要区域。它是一种遵循后进先出(LIFO,Last In First Out)原则的存储结构,这意味着最后压入栈中的元素会第一个被弹出。
储存内容
函数调用的上下文信息(如函数参数、返回地址)。
局部变量(函数内部定义的变量)。
函数调用链(嵌套函数调用时,每个函数的调用信息存放在栈帧中)。
内存栈的操作
内存栈的操作基于后进先出(LIFO)的原则,通常包括以下几种操作:
压栈(Push)
当一个函数被调用时,操作系统会将该函数的执行上下文(包括局部变量、返回地址、函数参数等)压入栈中,这个过程叫做“压栈”。
栈顶指针向下移动(地址数值减小),为该函数分配相应的内存。
弹栈(Pop)
当函数执行完毕,操作系统会从栈顶弹出该函数的上下文,恢复之前的状态,这个过程叫做“弹栈”。
栈顶指针向上移动(地址数值增大),释放该函数的内存,供其他函数调用使用。
栈帧(Stack Frame)
每次函数调用时,系统会为该函数创建一个栈帧,栈帧是栈上的一个区域,专门用于存储该函数的局部数据和调用信息。
栈帧中通常包含:
- 返回地址:用于返回调用函数的位置。
- 函数参数:函数的输入数据。
- 局部变量:函数内部的局部变量。
- 保存的寄存器值:在函数执行时保存当前寄存器的状态,以便函数执行完毕后恢复。
栈顶指针(Stack Pointer)和帧指针(Frame Pointer)
- 栈顶指针(SP, Stack Pointer):指向当前栈的顶部,用于管理栈的增长和收缩。
- 帧指针(FP, Frame Pointer):指向当前栈帧的起始位置,用于访问函数参数和局部变量。
特点
- 后进先出(LIFO)结构
内存栈遵循后进先出(LIFO)的结构原则,最后入栈的数据最先弹出。这与函数调用的顺序相匹配,确保函数按照调用的反顺序依次返回。
- 自动分配和释放
内存栈的内存分配和释放是自动管理的,当函数调用时分配内存,函数返回时自动释放内存,无需程序员手动管理。这与堆内存不同,堆内存需要程序员手动释放。
指令
常见的指令大致有:
- 数据传输指令
用于在不同的存储区域之间移动数据,比如在寄存器、内存和外部设备之间传输。
- MOV(Move)
作用:将一个操作数的值传输到另一个位置。
格式:MOV 目的操作数, 源操作数
例子:MOV AX, BX
含义:将寄存器BX中的数据复制到寄存器AX中。
原理:操作系统通过总线系统将源操作数的数据放入目的操作数中。这并不是简单地交换数据,而是复制数据。 - PUSH(入栈)
作用:将一个操作数的值压入栈中。
格式:PUSH 操作数
例子:PUSH AX
含义:将寄存器AX的内容压入栈顶。
原理:处理器会将栈指针(SP)的值减小,并将AX的数据存入新的栈顶位置。 - POP(出栈)
作用:从栈顶弹出一个操作数的值。
格式:POP 操作数
例子:POP AX
含义:将栈顶的值弹出,并存入寄存器AX中。
原理:处理器将栈顶的内容存入目的寄存器,同时栈指针(SP)的值增大,表示栈顶位置的变化。 - LOAD
作用:从内存中读取数据到寄存器中。
格式:LOAD 目的寄存器, 地址
例子:LOAD AX, [1234]
含义:从内存地址1234中读取数据,并将其存入寄存器AX中。
原理:处理器通过地址总线找到内存中的具体位置,将数据读取并存入寄存器。 - STORE
作用:将寄存器的数据写入到内存中。
格式:STORE 地址, 寄存器
例子:STORE [1234], AX
含义:将寄存器AX中的数据存入内存地址1234中。
原理:处理器通过地址总线定位到内存中的指定位置,然后通过数据总线将寄存器的数据写入到该位置。
- 算术运算指令
用于执行基本的数学运算,如加法、减法、乘法和除法。
- ADD(加法)
作用:对两个操作数执行加法运算。
格式:ADD 目的操作数, 源操作数
例子:ADD AX, BX
含义:将寄存器BX和AX中的数据相加,结果存入AX。
原理:处理器的算术逻辑单元(ALU)负责进行加法操作。它将两个操作数进行二进制相加,并更新处理器的标志位。 - SUB(减法)
作用:对两个操作数执行减法运算。
格式:SUB 目的操作数, 源操作数
例子:SUB AX, BX
含义:将寄存器BX中的数据从AX中减去,结果存入AX。
原理:处理器的ALU进行二进制减法运算,结果存储在目的操作数,并更新相关的标志位。 - MUL(乘法)
作用:对两个操作数执行无符号乘法运算。
格式:MUL 源操作数
例子:MUL BX
含义:将寄存器AX中的数据和BX中的数据相乘,结果存入寄存器AX和DX。
原理:ALU进行二进制乘法,并根据乘法结果将高位存储在DX,低位存储在AX。 - DIV(除法)
作用:对两个操作数执行无符号除法运算。
格式:DIV 源操作数
例子:DIV BX
含义:将寄存器AX和DX中的数据作为被除数,BX为除数,商存入AX,余数存入DX。
原理:处理器将两个寄存器的组合数据作为被除数,执行二进制除法。
- 逻辑运算指令
用于执行按位逻辑操作,例如与(AND)、或(OR)、非(NOT)等。
- AND(按位与)
作用:对两个操作数执行按位与运算。
格式:AND 目的操作数, 源操作数
例子:AND AX, BX
含义:对AX和BX中的数据进行按位与操作,结果存入AX。
原理:AND运算将两个操作数按位进行比较,当且仅当两个对应位都为1时,结果为1,否则为0。 - OR(按位或)
作用:对两个操作数执行按位或运算。
格式:OR 目的操作数, 源操作数
例子:OR AX, BX
含义:对AX和BX中的数据进行按位或操作,结果存入AX。
原理:OR运算将两个操作数按位进行比较,只要有一个位为1,结果为1,否则为0。 - XOR(按位异或)
作用:对两个操作数执行按位异或运算。
格式:XOR 目的操作数, 源操作数
例子:XOR AX, BX
含义:对AX和BX中的数据进行按位异或操作,结果存入AX。
原理:当两个对应的二进制位 不相同时,结果为1;当两个对应的二进制位 相同时,结果为0。 - NOT(按位取反)
作用:对操作数的每个位进行取反操作。
格式:NOT 操作数
例子:NOT AX
含义:对AX中的每个位进行取反操作。
原理:NOT运算将每个位的1变为0,0变为1。
- 控制指令
用于改变程序执行的流程,比如跳转、函数调用等。
- JMP(无条件跳转)
作用:无条件地将程序控制权转移到指定地址。
格式:JMP 地址
例子:JMP 1234H
含义:程序的执行跳转到内存地址1234H。
原理:处理器将程序计数器(PC)设置为指定地址,使程序从该地址继续执行。 - CALL(调用子程序)
作用:调用一个子程序,并在执行完成后返回。
格式:CALL 地址
例子:CALL 5678H
含义:调用位于地址5678H的子程序,子程序完成后返回。
原理:处理器将当前程序计数器的值压入栈中,然后跳转到子程序地址。子程序执行完后,通过RET指令返回原来的位置。 - RET(返回)
作用:从子程序返回到主程序。
格式:RET
原理:从栈中弹出返回地址,并跳转到该地址继续执行主程序。
- 输入/输出指令
用于与外部设备交换数据,如从键盘读取输入,向显示器输出结果。
- IN(输入)
作用:从指定的I/O端口读取数据。
格式:IN 寄存器, 端口
例子:IN AX, 60H
含义:从端口60H读取数据并存入寄存器AX中。
原理:通过I/O总线从外部设备读取数据并放入寄存器。 - OUT(输出)
作用:将寄存器中的数据输出到指定的I/O端口。
格式:OUT 端口, 寄存器
例子:OUT 60H, AX
含义:将寄存器AX中的数据输出到端口60H。
原理:通过I/O总线将寄存器的数据发送到外部设备。
- 条件控制指令
用于根据某个条件是否成立来决定是否跳转执行另一段代码。
JZ(如果零则跳转)
作用:如果零标志位(ZF)为1,则跳转到指定地址。
格式:JZ 地址
例子:JZ 1234H
含义:如果前一条指令的结果为0,则跳转到地址1234H。
原理:处理器检查零标志位,如果标志位为1,则改变程序计数器的值以跳转。JNZ(如果非零则跳转)
作用:如果零标志位(ZF)为0,则跳转到指定地址。
格式:JNZ 地址
例子:JNZ 5678H
含义:如果前一条指令的结果不为0,则跳转到地址5678H。
原理:检查零标志位是否为0,如果为0则程序继续从指定地址执行。
分析
push 0x68 //将0x68 意为h压入栈顶 |
pwn中的gadgets
在pwn(利用漏洞攻击)领域,gadget 是指二进制文件中可以用作执行代码的小段汇编指令序列。它们通常以“RET”指令结尾,并且是ROP(Return Oriented Programming)攻击中非常关键的组成部分。
ROP链中的 Gadget
一个典型的 ROP 链由多个 gadget 组成,这些 gadget 被连接起来以实现复杂的功能。例如,一个 gadget 可以用来将一个特定值加载到某个寄存器,另一个 gadget 用来执行 syscall(系统调用)。通过这种方式,攻击者能够绕过现代系统中的多种安全机制,如NX (Non-Executable Stack) 和 **ASLR (Address Space Layout Randomization)**。
假设一个 gadget 是这样的:
pop eax; ret; |
这个 gadget 会从栈中弹出一个值到 eax 寄存器,然后通过 ret 指令将控制权交回栈上下一个地址。如果通过精心构造栈帧,攻击者可以反复控制寄存器和程序流程,执行任意的代码。
1. pop rdi; ret |
gadgets有
1. pop rdi; ret |
Linux系统调用
在Linux操作系统中,系统调用(system call) 是用户程序与内核进行交互的主要方式。用户态程序通过系统调用向内核请求特定服务(如文件操作、进程管理、内存分配等)。每个系统调用都有一个唯一的编号(System Call Number),通过这个编号,程序可以告诉内核它想要执行的操作。
Linux系统调用概述
定义
系统调用定义:
系统调用是用户程序与操作系统内核交互的接口。当用户态的程序需要执行一些受操作系统管理的操作时(如SYS_read,SYS_write,SYS_open等操作文件或设备的输入输出)。用户态的程序无法直接访问内核态的资源,需要通过系统调用向内核请求这些操作。系统调用号
是内核为每个系统调用分配的唯一标识符。当程序希望执行某个系统调用时,它需要将对应的系统调用号告诉内核,以便内核执行相应的操作。
常见的系统调用号(64位)
- SYS_read: 编号为
0,读取文件内容。 - SYS_write: 编号为
1,写入数据到文件或设备 - SYS_open: 编号为
2,打开文件, - SYS_close: 编号为
3,关闭文件
32位
- SYS_read: 编号为
0x0. - SYS_write: 编号为
0x04 - SYS_open: 编号为
0x05 - SYS_close: 编号为
0x06
- SYS_read: 编号为
常见的系统调用号的使用
在了解这一知识前,我们要先了解文件描述符(File Descriptor, fd)
文件描述符fd
文件描述符fd:是在操作系统中用于标识和管理文件、管道、套接字等对象的一个整数值。
常见的有:
- 0:
stdin(标准输入)— 通常对应于键盘输入。 - 1:
stdout(标准输出)— 通常对应于终端输出。 - 2:
stderr(标准错误)— 通常用于输出错误信息。
SYS_read
x86-64架构下:
RAX:系统调用号 (0)RDI:文件描述符RSI:缓冲区指针RDX:读取的字节数
mov rax, 0 ; 系统调用号 0 -> SYS_read |
32 位架构下:
EAX:系统调用号 (3)EBX:文件描述符ECX:缓冲区指针EDX:读取的字节数mov eax, 3 ; 系统调用号 3 -> SYS_read
mov ebx, file_desc ; 文件描述符
mov ecx, buffer ; 缓冲区
mov edx, buffer_size ; 读取的字节数
int 0x80 ; 触发系统调用
SYS_write
x86-64架构下:
RAX:系统调用号 (1)RDI:文件描述符RSI:缓冲区指针RDX:写入的字节数
mov rax, 1 ; 系统调用号 1 -> SYS_write |
32 位架构下:
EAX:系统调用号 (4)EBX:文件描述符ECX:缓冲区指针EDX:写入的字节数
mov eax, 4 ; 系统调用号 4 -> SYS_write |
SYS_open
x86-64架构下:
RAX:系统调用号 (2)RDI:文件路径的指针(字符串)RSI:文件标志(如只读、读写等)RDX:权限模式(如权限 644)
mov rax, 2 ; 系统调用号 2 -> SYS_open |
32 位架构下:
EAX:系统调用号 (5)EBX:文件路径的指针(字符串)ECX:文件标志(如只读、读写等)EDX:权限模式(如权限 644)
mov eax, 5 ; 系统调用号 5 -> SYS_open |
SYS_close
SYS_close 用于关闭文件描述符。系统调用号为 3,参数为文件描述符。
x86-64架构下:
RAX:系统调用号 (3)RDI:文件描述符
mov rax, 3 ; 系统调用号 3 -> SYS_close |
32 位架构下:
EAX:系统调用号 (6)EBX:文件描述符
mov eax, 6 ; 系统调用号 6 -> SYS_close |
系统调用在x86和x86-64架构下的调用约定
x86架构(32位)系统调用约定
在32位的x86架构中,Linux使用了中断指令 int 0x80 来触发系统调用。调用约定如下:
系统调用触发:
使用int 0x80触发系统调用。该指令会切换CPU执行模式,从用户态进入内核态。参数传递:
系统调用编号和参数通过寄存器传递:- eax:存储系统调用编号(System Call Number)
- ebx:第1个参数
- ecx:第2个参数
- edx:第3个参数
- esi:第4个参数
- edi:第5个参数
- ebp:第6个参数
返回值:
系统调用的返回值存储在eax寄存器中,并返回用户态程序。
例子:
例如,write 系统调用的系统调用编号是1,调用方式如下:
mov eax, 4 ; 系统调用编号 4 对应 write |
x86-64架构(64位)系统调用约定
在x86-64(64位)架构上,Linux引入了新的 syscall 指令来替代 int 0x80。64位系统的寄存器和调用约定也有所不同。
系统调用触发:
使用syscall指令触发系统调用。参数传递:
系统调用编号和参数通过以下寄存器传递:- rax:存储系统调用编号
- rdi:第1个参数
- rsi:第2个参数
- rdx:第3个参数
- r10:第4个参数
- r8:第5个参数
- r9:第6个参数
需要注意的是,r10 代替了32位架构中的 rcx。
返回值:
系统调用的返回值存储在rax寄存器中。
例子:
例如,write 系统调用在64位系统中的调用方式如下:
mov rax, 1 ; 系统调用编号 1 对应 write |
总结:x86 vs x86-64系统调用约定对比
| 特性 | x86(32位) | x86-64(64位) |
|---|---|---|
| 系统调用触发方式 | int 0x80 |
syscall |
| 系统调用编号寄存器 | eax |
rax |
| 参数寄存器 | ebx, ecx, edx, esi, edi, ebp |
rdi, rsi, rdx, r10, r8, r9 |
| 返回值寄存器 | eax |
rax |
| 最大参数数量 | 6 | 6 |
| 堆栈使用 | 使用堆栈传递更多参数 | 使用寄存器传递更多参数 |
如表格所示,划线部分为x86和x86—64的具体区别
compiled on an x86 architecture machine, memcpy
_BYTE *__cdecl memcpy(_BYTE *a1, _BYTE *a2, unsigned int a3) |
开头定义函数,接收三个参数,目标地址 a1,源地址 a2,以及要复制的字节数 a3。其中,a1储存在edi,a2储存在esi,a3贮存在ecx。
compiled on an x86-64 architecture machine, mmap64
unsigned __int64 __fastcall mmap64( |
指定长度a3大小的字符串,从源地址a2复制到a1
compiled on an x86-64 architecture machine, sys_clone
v7 = sys_clone(0x100011uLL, 0LL, &parent_tid, v5); |
v7是rax,用来储存返回值,0x100011uLL是第一个参数,0x100011是防止生成空格,ull是unsign long long,用于指定克隆的内容。0ll,其中ll是long long,0是指long long 类型的值为0,意思是默认设置。&parent_tid是只想变量的指针,用于储存原先跑线程的内容。v5是第四个参数,是r10
compiled on an x86-64 architecture machine, printf (bonus)
__int64 printf(__int64 a1, ...) |
开头定义函数printf,接收至少一个参数a1。定义一个类型为gcc_va_list的变量,va。随后初始化va,方便从a1内读取数据,返回vfprintf函数,将输出目标设置为stdout,输出va的内容
虚拟内存和ELF文件
虚拟内存
什么是虚拟内存
虚拟内存是一种内存管理技术,它为每个进程创建一个虚拟地址空间,这个空间看似独立于物理内存,允许每个进程认为自己拥有完整的内存资源。
作用:
- 地址空间隔离: 每个进程在虚拟内存系统中都会拥有自己的独立的虚拟地址空间。这样可以避免不同进程互相干扰,增强系统安全性。比如,一个进程无法直接访问另一个进程的内存,避免了潜在的安全漏洞。
- 简化内存管理: 虚拟内存给进程提供了一个连续的虚拟地址空间,即使物理内存并不是连续的。操作系统可以通过页表将虚拟地址映射到不连续的物理内存位置,使得程序员和进程不用关心底层物理内存的实际分配情况。
- 内存扩展(内存换页/交换): 虚拟内存允许进程使用的地址空间大于实际的物理内存容量。当物理内存不足时,操作系统可以将不常用的页面暂时存储在硬盘中,称为交换(swapping)或 分页(paging)。这样,虚拟内存可以扩展可用的内存空间,允许运行更大的程序。
核心概念
虚拟地址空间(Virtual Address Space)
- 每个进程在其执行时都拥有一个独立的虚拟地址空间,该空间与物理内存是独立的。虚拟地址空间使得程序认为它可以使用更多的内存,甚至超过了实际的物理内存容量。
映射
- 处理器将虚拟地址分为多个部分,包括页号和页内偏移量,通过页表找到虚拟页对应的物理页,找到映射后,将虚拟地址翻译为物理地址,进而访问物理内存中的数据。
分页
- 虚拟内存通过将物理内存划分为大小固定的“页”(通常为4KB),并为每个进程分配虚拟内存页。虚拟内存页并不需要与物理内存连续对齐,这样可以更高效地利用内存空间。
页表
- 页表是虚拟地址与物理地址的映射表。每个进程都有自己的页表,记录着虚拟内存页和对应的物理内存页之间的对应关系。操作系统和硬件共同管理页表,保证地址转换的正确性。
页面置换
当物理内存不足时,操作系统会将不活跃的内存页存储到硬盘上的交换空间中,以腾出物理内存。此过程称为页面置换,当需要再次访问这些被置换的页时,系统会将它们重新加载到内存中。
虚拟内存的运行原理
- 虚拟地址到物理地址的转换分为两种情况
- 当一个程序访问虚拟地址时,处理器会首先检查页表中的映射,看看该虚拟地址是否有对应的物理地址。如果有映射,虚拟地址会被转换为物理地址,程序即可访问对应的内存位置。
- 如果没有找到对应的物理地址(例如该虚拟页不在物理内存中,或页表中没有记录),处理器会发出缺页异常(Page Fault),请求操作系统处理。
- 处理缺页异常
- 当发生缺页异常时,操作系统会检查该虚拟页是否已经存在于硬盘的交换区中。如果存在,操作系统会将该页从硬盘加载到内存中,并更新页表,以反映新的映射。
- 如果物理内存已满,操作系统会选择一个不常用的页,将其内容写入硬盘,并释放该页的内存空间,再将新页载入物理内存。这称为页面置换。
- TLB(快速缓存映射)
- 虚拟地址转换频繁发生,使用页表查找每次都会带来较高的性能开销。为了加快这一过程,CPU内部使用TLB(Translation Lookaside Buffer)缓存最近的虚拟地址到物理地址的映射。当程序访问内存时,CPU首先查询TLB,若找到匹配的映射,就可以快速完成地址转换;若没有命中TLB,才会查询页表。
- 分页和分段
- 虚拟内存通常通过分页的方式进行管理,但也可以通过分段(Segmentation)方式,按照程序的不同逻辑部分(如代码段、数据段、堆栈段)来分割内存。这种分段方式较少使用,现代系统大多以分页为主。
- 交换空间(Swap Space)
- 当物理内存不足时,系统会将一些不常用的内存页写入硬盘的交换空间中,这样可以为其他程序腾出更多的内存。当需要再次访问被换出的页时,操作系统会将其从交换区重新加载到内存中,这种技术允许系统运行超过物理内存容量的多个进程。
虚拟内存和物理内存
| 虚拟内存 | 物理内存 | |
|---|---|---|
| 定义 | 操作系统提供的抽象地址空间,进程看到的“内存” | 计算机实际的物理内存,例如RAM |
| 地址空间 | 每个进程都有独立的虚拟地址空间 | 物理地址空间是唯一的,由硬件直接管理 |
| 大小 | 理论上可以比物理内存大,通过交换空间扩展 | 受限于系统实际的内存大小 |
| 分配 | 虚拟内存是连续的,但可以映射到不连续的物理内存上 | 物理内存是有限的,有可能是分散的 |
| 保护控制 | 虚拟内存有内存保护机制,防止进程之间的干扰 | 没有直接的隔离和保护机制 |
| 访问机制 | 通过页表实现的访问控制,每个进程由自己的权限 | 受硬件控制,一般直接映射 |
| 内存管理单位 | 以页(4kb或更大)为单位 | 按字节或块进行管理 |
| 扩展性 | 通过硬盘交换文件扩展 | 无法扩展 |
ELF文件
概述与分类
ELF(Executable and Linkable Format)
是Unix及类Unix操作系统中使用的一种文件格式,用于可执行文件、目标文件和共享库,广泛用于Linux系统中,与windows系统的PE文件类似。
正如其名,ELF文件有着两个特性,一是Executable(可执行性),二是Linking(可连接性)
ELF文件分为三种:
可重定位文件(Relocatable,.o)
译器和汇编器生成的中间文件,通常扩展名为
.o。每个源代码文件经过编译器编译后,都会生成对应的.o文件,里面包含目标代码和必要的符号信息。在链接阶段将多个源文件组合成一个完整的程序。Linker(链接器)会将这些可重定位文件结合起来,解决符号依赖(如函数调用和全局变量引用),生成最终的可执行文件或共享对象文件。
可执行文件(Executable)
可执行文件是由链接器将多个可重定位文件链接而成的,通常是程序的最终输出,可直接被操作系统加载和执行。
当用户执行程序时,操作系统会将可执行文件加载到虚拟内存中,开始执行。
共享对象文件(Shared Object ,.so)
通常用于实现共享库(如
.so文件)。共享库中的代码可以在多个程序中共享,避免每个程序都将相同的库代码静态链接到自己的可执行文件中。程序运行时动态加载(动态链接),也可以在链接时与其他可重定位文件一起静态链接到最终的可执行文件中。
ELF文件格式的核心概念
ELF Header(ELF头部)
- 作用:包含有关该文件的基础信息,如文件类型(可重定位文件、可执行文件、共享库)、目标体系结构(32位或64位)、程序入口地址等。它还指向程序头表和节头表的偏移地址。
Program Header Table(程序头表)
- 作用:描描述了如何将文件中的段加载到内存中。程序头表对链接器和加载器非常重要,它指示系统如何创建进程的虚拟地址空间。
Sections(节区)
- 作用:节是ELF文件中的逻辑分区,常见的节包括
.text(代码段)、.data(数据段)、.bss(未初始化的数据段)等
Segments(段)
- 作用:ELF文件运行时由节区映射形成的内存区域,是ELF文件中的一块内存区域,用于执行的代码或数据。
Section Header(节头表)
- 作用:描述了文件的各个节(section)的位置和大小。这些节包括代码段、数据段、符号表、字符串表等。该表主要用于链接和调试,不用于程序的实际执行。
Linking View 和 Execution View
| 链接视角 | 执行视角 |
|---|---|
| ELF Header | ELF Header |
| Program Header Table | Program Header Table |
| Sections 1 | Segments 1 |
| Sections 2 | Segments 2 |
| ——- | ——- |
| Sections n | Segments n |
| Section Header | Section Header |
如上述表格所示,
链接视角由头部,程序头表,节区和节头表组成,程序头表可选
执行视角由头部,程序头表,节区和节头表组成,节头表可选
Linking View是编译器和链接器在生成目标文件和可执行文件时所使用的文件组织方式。主要包含各个不同的段,这些段对链接器有意义。
常见的ELF段:
- .text:存放程序的可执行指令。
- .data:存放已初始化的全局变量和静态变量。
- .bss:存放未初始化的全局变量和静态变量,在程序运行时会被清零,在文件中不占据实际空间。
- .rodata:存放只读数据,如静态变量,字符串常量以及“count“修饰的变量等。
- .symtab:符号表,记录函数和变量的名称、地址、大小等信息。
- .strtab和 .strtab:字符串表,存放符号的名字等字符串。
- .rel.dyn / .rela.dyn:动态链接时的重定位信息。
段表通过 Section Header Table 描述,每个段的内容在文件中可能是分散的
Execution View描述的是程序在运行时的内存布局,通过Program Header Table来描述。每个程序头对应一个内存区域(段),并且包含如何将文件内容映射到虚拟内存的细节。
常见的程序头类型:
- PT_LOAD:描述需要加载到内存的段,指定文件偏移、虚拟地址、物理地址、文件大小和内存大小。
- PT_DYNAMIC:动态链接信息段,包含动态库加载时的相关信息。
- PT_INTERP:指定动态链接器的位置,一般在动态链接的ELF文件中存在。
- PT_NOTE:包含调试信息和其他注释。
- PT_TLS:线程本地存储段,存放线程私有的变量。
在执行时,操作系统的加载器根据程序头表将文件的各个部分加载到内存中,不同类型的段会映射到不同的内存区域,形成可执行的进程映像。
附件分析
- IDA PRO
{ |
使用了危险函数read,buf的大小为256字节,但read函数却试图读取最多512字节的数据。
- pwndgb
使用远程调试,先输入 gdb ./cst, 设置断点b *vuln,开始start,再si进入vuln,在输入disasemble vuln反汇编查看地址。再用set *0x401223=0x61,再看x/20b $rsi 查看是否覆盖成功。
- pwntools
vim 创建文档,
from pwn import * |
4104是哪里来的,根据char buf[256]; // [rsp+0h] [rbp-100h] BYREF buf离栈底100h,转换为十进制为4096,再加上64位的偏移8
所以我们要输入4104个a,
地址